![]()
Spectral Siren Population Inference on GWTC-3#
The thrid gravitational-wave transient catalog GWTC-3 includes all compact binary coalescences observed during Advanced LIGO/Virgo’s first three oberving runs.
“Spectral siren” cosmology (see, e.g., Ezquiaga & Holz) uses features in the black hole mass spectrum to constrain the distance-redshift relation.
GWPopulation builds upon Bilby (arXiv:1811.02042) to provide simple, modular, user-friendly, population inference. wcosmo provides optimized cosmology functionality for GWPopulation.
There are many implemented models and an example of defining custom models is included below. In this example we use:
A mass distribution in primary mass and mass ratio from Talbot & Thrane (2018) (arXiv:1801:02699). This is equivalent to the
PowerLaw + Peakmodel used in LVK analyses without the low-mass smoothing for computational efficiency.Half-Gaussian + isotropic spin tilt distribution from Talbot & Thrane (2017) (arXiv:1704.08370).
Beta spin magnitude distribution from Wysocki+ (2018) (arXiv:1805:06442).
Each of these are also available with independent but identically distributed spins.
Redshift evolution model as in Fishbach+ (2018) (arXiv:1805.10270).
A variable Flat Lambda CDM cosmology using a modified version of the approximation in arXiv:1111.6396 as implemented in
wcosmo.
For more information on GWPopulation see the git repository, documentation.
Setup#
If you’re using colab.research.google.com you will want to choose a GPU-accelerated runtime (I’m going to use a T4 GPU).
“runtime”->”change runtime type”->”Hardware accelerator = GPU”
Install some needed packages#
Almost all of the dependencies for this are integrated into GWPopulation. These include wcosmo for cosmology, and Bilby and dynesty for sampling.
The one exception is `unxt <https://unxt.readthedocs.io/en/latest/>`__ which provides astropy-like units compatible with jax.
[1]:
!pip install "gwpopulation>=1.3" unxt --quiet --progress-bar off
Download data#
We need to download the data for the events and simmulated “injections” used to characterize the detection sensitivity.
Event posteriors#
We’re using the posteriors from the GWTC-3 data release in a pre-processed format.
The file was produced by gwpopulation-pipe to reduce the many GB of posterior sample files to a single ~30Mb file.
The choice of events in this file was not very careful and should only be considered qualitatively correct.
The data file can be found here. The original data can be found at zenodo:5546663 and zenodo:6513631 along with citation information.
Sensitivity injections#
Again I have pre-processed the full injection set using gwpopulation-pipe to reduce the filesize. The original data is available at zenodo:7890398 along with citation information.
[2]:
!gdown https://drive.google.com/uc?id=16gStLIjt65gWBkw-gNOVUqNbZ89q8CLF
!gdown https://drive.google.com/uc?id=10pevUCM3V2-D-bROFEMAcTJsX_9RzeM6
Downloading...
From: https://drive.google.com/uc?id=16gStLIjt65gWBkw-gNOVUqNbZ89q8CLF
To: /content/gwtc-3-injections.pkl
100% 2.69M/2.69M [00:00<00:00, 32.8MB/s]
Downloading...
From: https://drive.google.com/uc?id=10pevUCM3V2-D-bROFEMAcTJsX_9RzeM6
To: /content/gwtc-3-samples.pkl
100% 36.4M/36.4M [00:01<00:00, 33.5MB/s]
Imports#
Import the packages required for the script. We also set the backend for array operations to jax which allows us to take advantage of just-in-time (jit) compilation in addition to GPU-parallelisation when available.
[3]:
import bilby as bb
import gwpopulation as gwpop
import jax
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from bilby.core.prior import PriorDict, Uniform
from gwpopulation.experimental.cosmo_models import CosmoModel
from gwpopulation.experimental.jax import JittedLikelihood
from wcosmo.astropy import Planck15
from wcosmo.utils import disable_units
disable_units()
gwpop.set_backend("jax")
xp = gwpop.utils.xp
%matplotlib inline
Load posteriors#
We remove two events from the file that shouldn’t be there that have NS-like secondaries as we are just interested in BBHs for this demonstration.
We also need to modify some of the stored parameters as we are going to include a cosmological fit so we will fit detector frame masses and luminosity distance.
When using the JAX backend, this could probably be accelerated by sprinkling some jax.jits.
[4]:
posteriors = pd.read_pickle("gwtc-3-samples.pkl")
del posteriors[15]
del posteriors[38]
for post in posteriors:
zs = post.pop("redshift").values
post["mass_1_detector"] = post.pop("mass_1") * (1 + zs)
post["luminosity_distance"] = np.asarray(Planck15.luminosity_distance(zs))
post["prior"] /= np.asarray(Planck15.dDLdz(zs) * (1 + zs))
Load injections#
Load the injections used to characterize the sensitivity of the gravitaitonal-wave survey.
Again, we need to make some modifications for fitting in detector-frame quantities.
[5]:
import dill
with open("gwtc-3-injections.pkl", "rb") as ff:
injections = dill.load(ff)
zs = np.asarray(injections.pop("redshift"))
injections["mass_1_detector"] = injections.pop("mass_1") * (1 + zs)
injections["luminosity_distance"] = np.asarray(Planck15.luminosity_distance(zs))
injections["prior"] /= np.asarray(Planck15.dDLdz(zs) * (1 + zs))
Define some models and the likelihood#
We need to define Bilby Model objects for the numerator and denominator independently as these cache some computations interally.
Note that we are using a CosmoModel, this in an experimental feature and so the specific API may change in future, but the basic funcionality should be stable. We create a model that can infer the three parameters of wCDM.
The HyperparameterLikelihood marginalises over the local merger rate, with a uniform-in-log prior. The posterior for the merger rate can be recovered in post-processing.
We provide:
posteriors: a list ofpandasDataFrames.hyper_prior: our population model, as defined above.selection_function: anything which evaluates the selection function.
We can also provide:
conversion_function: this converts between the parameters we sample in and those needed by the model, e.g., for sampling in the mean and variance of the beta distribution.max_samples: the maximum number of samples to use from each posterior, this defaults to the length of the shortest posterior.
[6]:
model = CosmoModel(
model_functions=[
gwpop.models.mass.two_component_primary_mass_ratio,
gwpop.models.spin.iid_spin,
gwpop.models.redshift.PowerLawRedshift(cosmo_model="FlatwCDM"),
],
cosmo_model="FlatwCDM",
)
vt = gwpop.vt.ResamplingVT(model=model, data=injections, n_events=len(posteriors))
likelihood = gwpop.hyperpe.HyperparameterLikelihood(
posteriors=posteriors,
hyper_prior=model,
selection_function=vt,
)
Define our prior#
The mass model has eight parameters that we vary that are described in arXiv:1801:02699. This model is sometimes referred to as “PowerLaw+Peak”
The spin magnitude model is a Beta distribution with the usual parameterization, and the spin orientation model is a mixure of a uniform component and a truncated Gaussian that peaks at aligned spin. This combination is sometimes referred to as “Default”.
For redshift we use a model that looks like
Finally, we set priors on the three parameters of the wCDM model, \(H_0\) (the Hubble constant), \(\Omega_{m,0}\) (the matter fraction of the Universe at current time), \(w_0\) (the constant dark energy equation of state).
[7]:
priors = PriorDict()
# mass
priors["alpha"] = Uniform(minimum=-2, maximum=4, latex_label="$\\alpha$")
priors["beta"] = Uniform(minimum=-4, maximum=12, latex_label="$\\beta$")
priors["mmin"] = Uniform(minimum=2, maximum=2.5, latex_label="$m_{\\min}$")
priors["mmax"] = Uniform(minimum=80, maximum=100, latex_label="$m_{\\max}$")
priors["lam"] = Uniform(minimum=0, maximum=1, latex_label="$\\lambda_{m}$")
priors["mpp"] = Uniform(minimum=10, maximum=50, latex_label="$\\mu_{m}$")
priors["sigpp"] = Uniform(minimum=1, maximum=10, latex_label="$\\sigma_{m}$")
priors["gaussian_mass_maximum"] = 100
# spin
priors["amax"] = 1
priors["alpha_chi"] = Uniform(minimum=1, maximum=6, latex_label="$\\alpha_{\\chi}$")
priors["beta_chi"] = Uniform(minimum=1, maximum=6, latex_label="$\\beta_{\\chi}$")
priors["xi_spin"] = Uniform(minimum=0, maximum=1, latex_label="$\\xi$")
priors["sigma_spin"] = Uniform(minimum=0.3, maximum=4, latex_label="$\\sigma$")
priors["H0"] = Uniform(minimum=20, maximum=200, latex_label="$H_0$")
priors["Om0"] = Uniform(minimum=0, maximum=1, latex_label="$\\Omega_{m,0}$")
priors["w0"] = Uniform(minimum=-1.5, maximum=-0.5, latex_label="$w_{0}$")
priors["lamb"] = Uniform(minimum=-1, maximum=10, latex_label="$\\lambda_{z}$")
Just-in-time compile#
We JIT compile the likelihood object before starting the sampler. This is done using the gwpopulation.experimental.jax.JittedLikelihood class.
We then time the original likelihood object and the JIT-ed version. Note that we do two evaluations for each object as the first evaluation must compile the likelihood and so takes longer. (In addition to the JIT compilation, JAX compiles GPU functionality at the first evaluation, but this is less extreme than the full JIT compilation.)
[8]:
parameters = priors.sample()
likelihood.log_likelihood_ratio(parameters)
%time print(likelihood.log_likelihood_ratio(parameters))
jit_likelihood = JittedLikelihood(likelihood)
%time print(jit_likelihood.log_likelihood_ratio(parameters))
%time print(jit_likelihood.log_likelihood_ratio(parameters))
-262.40427928666327
CPU times: user 449 ms, sys: 171 ms, total: 620 ms
Wall time: 451 ms
-262.40427928666327
CPU times: user 12.1 s, sys: 502 ms, total: 12.6 s
Wall time: 12.1 s
-262.40427928666327
CPU times: user 20.6 ms, sys: 114 µs, total: 20.7 ms
Wall time: 21 ms
Run the sampler#
We’ll use the sampler dynesty and use a small number of live points to reduce the runtime (total runtime should be approximately 5 minutes on T4 GPUs via Google colab). The settings here may not give publication quality results, a convergence test should be performed before making strong quantitative statements.
bilby times a single likelihood evaluation before beginning the run, however, this isn’t well defined with JAX.
Note: sometimes this finds a high likelihood mode, likely due to breakdowns in the approximation used to estimate the likelihood. If you see dlogz > -80, you should interrupt the execution and restart.
[9]:
result = bb.run_sampler(
likelihood=jit_likelihood,
priors=priors,
sampler="dynesty",
nlive=100,
label="cosmo",
sample="acceptance-walk",
naccept=5,
save="hdf5",
resume=False,
)
20:18 bilby INFO : Running for label 'cosmo', output will be saved to 'outdir'
20:18 bilby INFO : Analysis priors:
20:18 bilby INFO : alpha=Uniform(minimum=-2, maximum=4, name=None, latex_label='$\\alpha$', unit=None, boundary=None)
20:18 bilby INFO : beta=Uniform(minimum=-4, maximum=12, name=None, latex_label='$\\beta$', unit=None, boundary=None)
20:18 bilby INFO : mmin=Uniform(minimum=2, maximum=2.5, name=None, latex_label='$m_{\\min}$', unit=None, boundary=None)
20:18 bilby INFO : mmax=Uniform(minimum=80, maximum=100, name=None, latex_label='$m_{\\max}$', unit=None, boundary=None)
20:18 bilby INFO : lam=Uniform(minimum=0, maximum=1, name=None, latex_label='$\\lambda_{m}$', unit=None, boundary=None)
20:18 bilby INFO : mpp=Uniform(minimum=10, maximum=50, name=None, latex_label='$\\mu_{m}$', unit=None, boundary=None)
20:18 bilby INFO : sigpp=Uniform(minimum=1, maximum=10, name=None, latex_label='$\\sigma_{m}$', unit=None, boundary=None)
20:18 bilby INFO : alpha_chi=Uniform(minimum=1, maximum=6, name=None, latex_label='$\\alpha_{\\chi}$', unit=None, boundary=None)
20:18 bilby INFO : beta_chi=Uniform(minimum=1, maximum=6, name=None, latex_label='$\\beta_{\\chi}$', unit=None, boundary=None)
20:18 bilby INFO : xi_spin=Uniform(minimum=0, maximum=1, name=None, latex_label='$\\xi$', unit=None, boundary=None)
20:18 bilby INFO : sigma_spin=Uniform(minimum=0.3, maximum=4, name=None, latex_label='$\\sigma$', unit=None, boundary=None)
20:18 bilby INFO : H0=Uniform(minimum=20, maximum=200, name=None, latex_label='$H_0$', unit=None, boundary=None)
20:18 bilby INFO : Om0=Uniform(minimum=0, maximum=1, name=None, latex_label='$\\Omega_{m,0}$', unit=None, boundary=None)
20:18 bilby INFO : w0=Uniform(minimum=-1.5, maximum=-0.5, name=None, latex_label='$w_{0}$', unit=None, boundary=None)
20:18 bilby INFO : lamb=Uniform(minimum=-1, maximum=10, name=None, latex_label='$\\lambda_{z}$', unit=None, boundary=None)
20:18 bilby INFO : gaussian_mass_maximum=100
20:18 bilby INFO : amax=1
20:18 bilby INFO : Analysis likelihood class: <class 'gwpopulation.experimental.jax.JittedLikelihood'>
20:18 bilby INFO : Analysis likelihood noise evidence: nan
20:18 bilby INFO : Single likelihood evaluation took 3.736e-04 s
20:18 bilby INFO : Using sampler Dynesty with kwargs {'nlive': 100, 'bound': 'live', 'sample': 'acceptance-walk', 'periodic': None, 'reflective': None, 'update_interval': 600, 'first_update': None, 'rstate': None, 'queue_size': 1, 'pool': None, 'use_pool': None, 'live_points': None, 'logl_args': None, 'logl_kwargs': None, 'ptform_args': None, 'ptform_kwargs': None, 'enlarge': None, 'bootstrap': None, 'walks': 100, 'facc': 0.2, 'slices': None, 'ncdim': None, 'blob': False, 'save_evaluation_history': False, 'history_filename': None, 'maxiter': None, 'maxcall': None, 'dlogz': 0.1, 'logl_max': inf, 'add_live': True, 'print_progress': True, 'print_func': <bound method Dynesty._print_func of <bilby.core.sampler.dynesty.Dynesty object at 0x78c93e511760>>, 'save_bounds': False, 'checkpoint_file': None, 'checkpoint_every': 60, 'resume': False, 'seed': None}
20:18 bilby INFO : Global meta data was removed from the result object for compatibility. Use the `BILBY_INCLUDE_GLOBAL_METADATA` environment variable to include it. This behaviour will be removed in a future release. For more details see: https://bilby-dev.github.io/bilby/faq.html#global-meta-data
20:18 bilby INFO : Checkpoint every check_point_delta_t = 600s
20:18 bilby INFO : Using dynesty version 3.0.0
20:18 bilby INFO : Generating initial points from the prior
20:18 bilby INFO : Using the bilby-implemented ensemble rwalk sampling method with an average of 5 accepted steps up to chain length 5000.
20:23 bilby INFO : Written checkpoint file outdir/cosmo_resume.pickle
20:23 bilby INFO : Rejection sampling nested samples to obtain 743 posterior samples
20:23 bilby INFO : Sampling time: 0:05:21.887630
20:23 bilby INFO : Summary of results:
nsamples: 743
ln_noise_evidence: nan
ln_evidence: nan +/- 0.404
ln_bayes_factor: -200.121 +/- 0.404
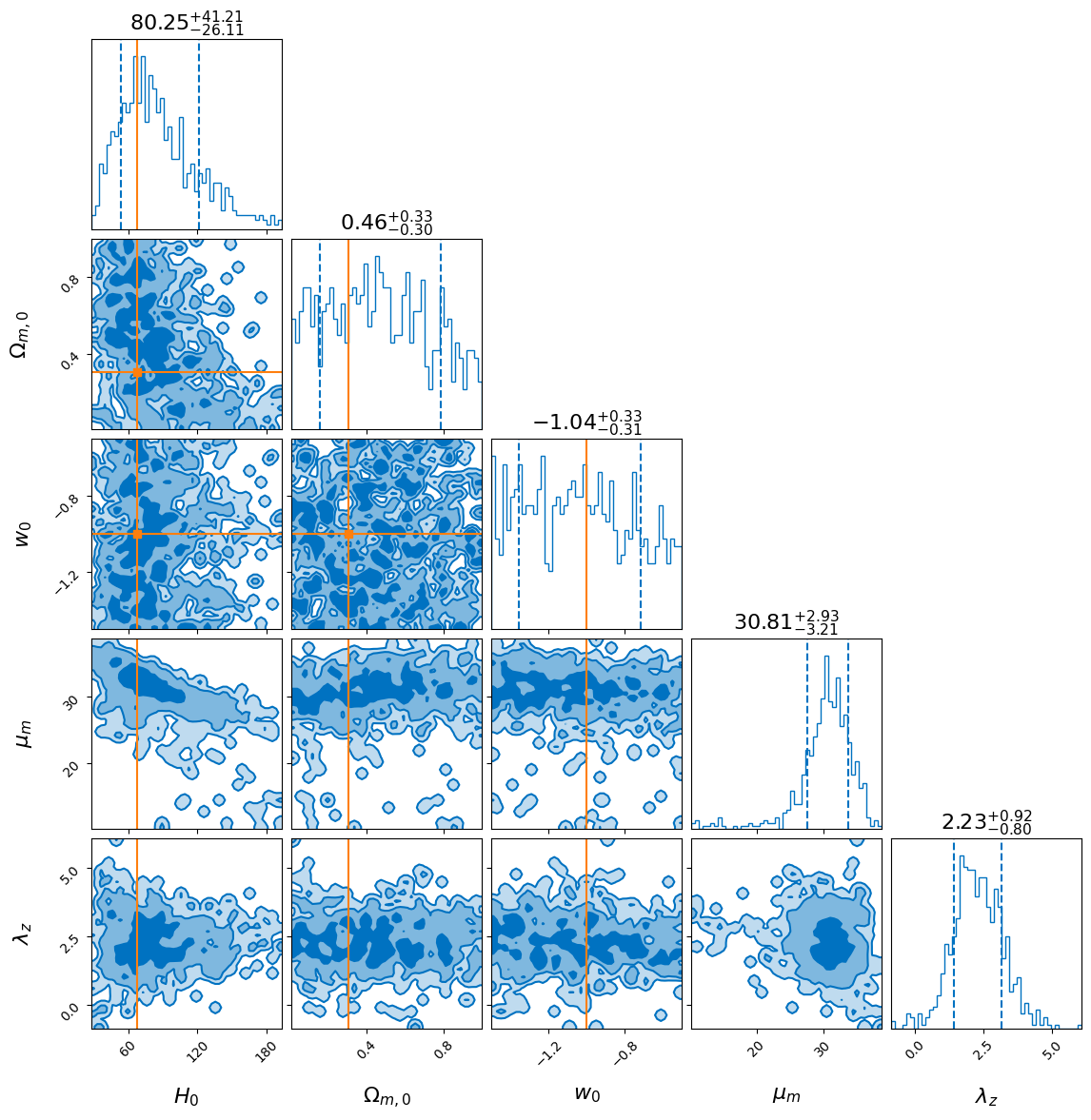
Plot some posteriors#
We can look at the posteriors on some of the parameters, here the cosmology parameters and the location of the mass peak and the redshift evolution.
We see that the value of the Hubble constant is strongly correlated with the location of the peak in the mass distribution as has been noted elsewhere.
We also include the values of the cosmology parameters reported in the Planck15 cosmology for reference.
[10]:
_ = result.plot_corner(
save=False,
parameters=["H0", "Om0", "w0", "mpp", "lamb"],
truths=[67.74, 0.3075, -1, np.nan, np.nan],
)
Post-processing checks#
As mentioned above, hierarchical analyses performed in this way are susceptible to systematic bias due to Monte Carlo error. To ensure we are not suffering from this issue, we compute the variance in each of our Monte Carlo integrals along with the total variance for each posterior sample. We then look at whether there are correlations between the log-likelihood, the variance, and the hyperparameters. If we see significant correlation between the variance and other quantities, it is a sign that our results may not be reliable.
[11]:
func = jax.jit(likelihood.generate_extra_statistics)
full_posterior = pd.DataFrame(
[func(parameters) for parameters in result.posterior.to_dict(orient="records")]
).astype(float)
full_posterior.describe()
[11]:
| H0 | Om0 | alpha | alpha_chi | amax | beta | beta_chi | gaussian_mass_maximum | lam | lamb | ... | var_67 | var_68 | var_69 | var_7 | var_70 | var_8 | var_9 | variance | w0 | xi_spin | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 743.000000 | 743.000000 | 743.000000 | 743.000000 | 743.0 | 743.000000 | 743.000000 | 743.0 | 743.000000 | 743.000000 | ... | 743.000000 | 743.000000 | 743.000000 | 743.000000 | 743.000000 | 743.000000 | 743.000000 | 743.000000 | 743.000000 | 743.000000 |
| mean | 92.360953 | 0.486399 | 2.770012 | 1.746442 | 1.0 | 1.762433 | 4.718197 | 100.0 | 0.112395 | 2.402824 | ... | 0.000807 | 0.001125 | 0.000445 | 0.000319 | 0.000676 | 0.000758 | 0.000865 | 1.320810 | -0.996708 | 0.612861 |
| std | 41.752044 | 0.255232 | 0.325525 | 0.431440 | 0.0 | 0.960041 | 0.868764 | 0.0 | 0.181103 | 0.902655 | ... | 0.000371 | 0.000574 | 0.000180 | 0.000121 | 0.000265 | 0.000303 | 0.000341 | 0.581550 | 0.277397 | 0.258564 |
| min | 27.361213 | 0.015903 | 0.073127 | 1.005281 | 1.0 | -0.623073 | 2.140122 | 100.0 | 0.007416 | -0.804947 | ... | 0.000178 | 0.000276 | 0.000143 | 0.000104 | 0.000157 | 0.000206 | 0.000215 | 0.364017 | -1.497507 | 0.000294 |
| 25% | 60.450052 | 0.289400 | 2.606277 | 1.405255 | 1.0 | 1.089937 | 4.137047 | 100.0 | 0.025116 | 1.876491 | ... | 0.000560 | 0.000718 | 0.000332 | 0.000241 | 0.000493 | 0.000562 | 0.000633 | 0.938326 | -1.228801 | 0.425478 |
| 50% | 81.385499 | 0.482400 | 2.794633 | 1.720532 | 1.0 | 1.708881 | 4.881393 | 100.0 | 0.036918 | 2.425547 | ... | 0.000740 | 0.001022 | 0.000406 | 0.000295 | 0.000637 | 0.000700 | 0.000802 | 1.166464 | -0.990194 | 0.652782 |
| 75% | 117.471092 | 0.682141 | 2.948939 | 2.048675 | 1.0 | 2.362898 | 5.420889 | 100.0 | 0.084015 | 2.993242 | ... | 0.000966 | 0.001403 | 0.000522 | 0.000370 | 0.000815 | 0.000911 | 0.001031 | 1.545677 | -0.763237 | 0.833905 |
| max | 199.657560 | 0.998753 | 3.664634 | 3.058372 | 1.0 | 6.947037 | 5.992614 | 100.0 | 0.984410 | 5.258572 | ... | 0.003369 | 0.005578 | 0.001749 | 0.001094 | 0.002131 | 0.002914 | 0.003131 | 5.849521 | -0.501485 | 0.998934 |
8 rows × 164 columns
[12]:
full_posterior[result.search_parameter_keys + ["log_likelihood", "variance"]].corr()
[12]:
| alpha | beta | mmin | mmax | lam | mpp | sigpp | alpha_chi | beta_chi | xi_spin | sigma_spin | H0 | Om0 | w0 | lamb | log_likelihood | variance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| alpha | 1.000000 | 0.104769 | 0.057727 | 0.031850 | -0.515273 | 0.119441 | -0.100635 | -0.003047 | 0.076560 | -0.021058 | 0.088277 | -0.064720 | -0.072049 | 0.075218 | 0.403147 | 0.185284 | 0.121324 |
| beta | 0.104769 | 1.000000 | 0.027970 | 0.061236 | -0.138127 | 0.077205 | -0.060520 | -0.075358 | -0.040275 | -0.048708 | -0.003847 | -0.145900 | 0.060501 | -0.015096 | -0.156298 | 0.036758 | 0.108856 |
| mmin | 0.057727 | 0.027970 | 1.000000 | 0.064558 | -0.011677 | 0.019201 | -0.074863 | -0.005770 | 0.051799 | -0.027292 | -0.043057 | 0.044674 | 0.017065 | 0.010939 | -0.053468 | 0.135694 | 0.101285 |
| mmax | 0.031850 | 0.061236 | 0.064558 | 1.000000 | 0.018959 | -0.038920 | 0.040200 | 0.010222 | 0.039795 | 0.018212 | -0.050326 | 0.039923 | 0.078974 | -0.018565 | 0.037521 | -0.047827 | -0.046889 |
| lam | -0.515273 | -0.138127 | -0.011677 | 0.018959 | 1.000000 | -0.769588 | 0.581677 | 0.032600 | -0.012777 | 0.056083 | -0.081695 | 0.619254 | -0.018853 | -0.041354 | 0.046305 | -0.454545 | -0.147537 |
| mpp | 0.119441 | 0.077205 | 0.019201 | -0.038920 | -0.769588 | 1.000000 | -0.755787 | -0.025355 | 0.002958 | -0.000804 | -0.008536 | -0.826711 | 0.073687 | 0.043599 | -0.216987 | 0.599396 | 0.245498 |
| sigpp | -0.100635 | -0.060520 | -0.074863 | 0.040200 | 0.581677 | -0.755787 | 1.000000 | -0.027702 | -0.079613 | -0.056792 | -0.067881 | 0.415370 | -0.080341 | -0.080442 | 0.165945 | -0.719298 | -0.477722 |
| alpha_chi | -0.003047 | -0.075358 | -0.005770 | 0.010222 | 0.032600 | -0.025355 | -0.027702 | 1.000000 | 0.663680 | -0.025392 | 0.278962 | -0.059012 | 0.032951 | 0.078771 | 0.105113 | -0.059531 | -0.103207 |
| beta_chi | 0.076560 | -0.040275 | 0.051799 | 0.039795 | -0.012777 | 0.002958 | -0.079613 | 0.663680 | 1.000000 | 0.025947 | 0.070095 | -0.056962 | 0.071960 | 0.025606 | 0.138051 | 0.110210 | 0.362311 |
| xi_spin | -0.021058 | -0.048708 | -0.027292 | 0.018212 | 0.056083 | -0.000804 | -0.056792 | -0.025392 | 0.025947 | 1.000000 | -0.063362 | 0.036526 | 0.053075 | -0.079162 | -0.036799 | 0.241529 | 0.177782 |
| sigma_spin | 0.088277 | -0.003847 | -0.043057 | -0.050326 | -0.081695 | -0.008536 | -0.067881 | 0.278962 | 0.070095 | -0.063362 | 1.000000 | -0.032461 | 0.042798 | 0.039152 | 0.194012 | -0.202366 | -0.259614 |
| H0 | -0.064720 | -0.145900 | 0.044674 | 0.039923 | 0.619254 | -0.826711 | 0.415370 | -0.059012 | -0.056962 | 0.036526 | -0.032461 | 1.000000 | -0.244578 | -0.066930 | 0.065973 | -0.387321 | -0.088668 |
| Om0 | -0.072049 | 0.060501 | 0.017065 | 0.078974 | -0.018853 | 0.073687 | -0.080341 | 0.032951 | 0.071960 | 0.053075 | 0.042798 | -0.244578 | 1.000000 | -0.062555 | 0.027233 | 0.043844 | 0.061437 |
| w0 | 0.075218 | -0.015096 | 0.010939 | -0.018565 | -0.041354 | 0.043599 | -0.080442 | 0.078771 | 0.025606 | -0.079162 | 0.039152 | -0.066930 | -0.062555 | 1.000000 | 0.049391 | 0.089234 | 0.004628 |
| lamb | 0.403147 | -0.156298 | -0.053468 | 0.037521 | 0.046305 | -0.216987 | 0.165945 | 0.105113 | 0.138051 | -0.036799 | 0.194012 | 0.065973 | 0.027233 | 0.049391 | 1.000000 | -0.082165 | 0.021441 |
| log_likelihood | 0.185284 | 0.036758 | 0.135694 | -0.047827 | -0.454545 | 0.599396 | -0.719298 | -0.059531 | 0.110210 | 0.241529 | -0.202366 | -0.387321 | 0.043844 | 0.089234 | -0.082165 | 1.000000 | 0.433768 |
| variance | 0.121324 | 0.108856 | 0.101285 | -0.046889 | -0.147537 | 0.245498 | -0.477722 | -0.103207 | 0.362311 | 0.177782 | -0.259614 | -0.088668 | 0.061437 | 0.004628 | 0.021441 | 0.433768 | 1.000000 |
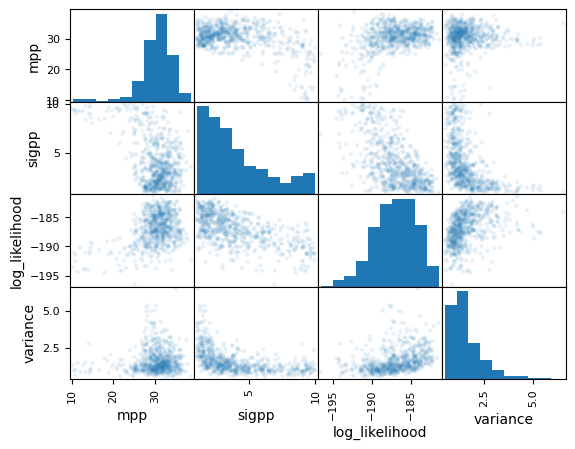
The most strongly correlated variables are the ones that control the position and width of the peak in the mass distribution. Below we show a scatter matrix for these variables. The variance for this analysis has a tail up to ~4 and so may be non-trivially biased. The simplest method to resolve this is by using more samples for all of the Monte Carlo integrals.
[13]:
pd.plotting.scatter_matrix(
full_posterior[["mpp", "sigpp", "log_likelihood", "variance"]],
alpha=0.1,
)
plt.show()
plt.close()
[13]: